Nel precedente articolo, la prima parte della spiegazione di Yudkowsky del Teorema di Bayes, si sono fatti una quantità di ragionamenti sulla probabilità (e sulla frequenza) di diversi tipi di eventi. In quel contesto tutti i passaggi sono descritti per esteso a parole, immagino per mantenere una maggior comprensibilità. Ad esempio, parlando della suddivisione di un campione di pazienti sulla base dei risultati della mammografia e della presenza o meno di un cancro al seno, veniva riportata la seguente tabella:
- Gruppo A: 80 donne con cancro al seno e positive alla mammografia.
- Gruppo B: 20 donne con cancro al seno e negative alla mammografia.
- Gruppo C: 950 donne senza cancro al seno e positive alla mammografia.
- Gruppo D: 8.950 donne senza cancro al seno e negative alla mammografia.
Ora, tutto questo va benissimo per spiegare il ragionamento a chi non conosce ancora i termini del problema ma, se uno deve davvero lavorare con questi numeri, queste descrizioni sono troppo prolisse. “Numero di donne con un cancro al seno e negative alla mammografia” è una descrizione un po’ troppo lunga per essere inserita in una formula.
Pensiamo ad esempio alla geometria. Il teorema di Pitagora dice che “in ogni triangolo rettangolo il quadrato costruito sull’ipotenusa ha la stessa area della somma delle aree dei quadrati costruiti sui cateti”. Oppure, ed è la stessa cosa, uno potrebbe dire: “In ogni triangolo rettangolo con cateti a e b ed ipotenusa c, 
Se poi diamo per assodato il contesto, magari perché di fianco c’è una figura con il triangolo rettangolo e le lettere che identificano i lati, la differenza diventa tra “il quadrato costruito sull’ipotenusa ha la stessa area della somma delle aree dei quadrati costruiti sui cateti” e “
Tornando al discorso sulle probabilità, le descrizioni verbali sono buone e giuste quando si sta cominciando ad affrontare un problema – sono addirittura fondamentali, in quanto permettono di chiarire esattamente i termini del problema – ma diventano un’inutile zavorra quando ci si è impratichiti del mezzo. Esistono quindi una serie di formalismi simbolici – niente paura, sono solo poche regolette – che conviene cominciare ad imparare subito, anche perché un paio di loro verranno già utilizzate nel prossimo articolo.
Tanto per cominciare, quando si discute di un problema come quello dei risultati della mammografia, è comodo sintetizzare le descrizioni dei sottoinsiemi del campione in simboli. In genere si usa una singola lettera maiuscola corsiva – A, B, C e così via – o una breve parola, possibilmente che rimandi al concetto che deve riassumere.
Nel nostro caso, ricordando che stiamo parlando di un campione di pazienti che hanno fatto uno screening mammografico, possiamo ad esempio chiamare M il concetto “positiva alla mammografia” e C il concetto “ha effettivamente un cancro al seno”.
La tabella che abbiamo appena visto può quindi essere sintetizzata come segue:
- Gruppo A: sia C che M (80 donne).
- Gruppo B: C ma non M (20 donne).
- Gruppo C: M ma non C (950 donne).
- Gruppo D: né M né C (8.950).
Dove per esempio la terza riga – “Gruppo C: M ma non C (950 donne)” – si legge: “Gruppo C: positive alla mammografia ma non hanno effettivamente un cancro al seno (950 donne)”. Che, come si vede, dice in parole leggermente diverse la stessa cosa della riga corrispondente della tabella originale.
Ai matematici piacciono un sacco i simboli, sono felici quando possono mettere un simbolo al posto di una parola! Pertanto introduciamo subito altri tre simboli che vedrete usare correntemente negli articoli su questo sito.
Il primo simbolo nuovo è “


Quindi la solita terza riga del nostro esempio può essere riscritta come “Gruppo C: 
Un altro simbolo che ci servirà subito è 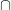
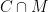
Il terzo simbolo molto utile, anche se non lo useremo nel nostro esempio, è 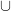
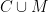
A questo punto possiamo riscrivere una terza volta la nostra tabella, in modo ancora più sintetico:
- Gruppo A:
- Gruppo B:
(20 donne).
- Gruppo C:
(950 donne).
- Gruppo D:
(8.950).
Fin qui abbiamo parlato di formalismi che permettono di combinare tra loro uno o più gruppi di soggetti. Come indichiamo la probabilità che un soggetto appartenga a un dato gruppo?

Quindi, utilizzando tutti i formalismi visti finora, la frase “la probabilità che una paziente con cancro al seno non risulti positiva alla mammografia” si può riassumere in “
Un’ultima notazione molto importante, su cui ritorneremo presto nella seconda parte dell’articolo di Yudkowsky, è quella relativa alla probabilità condizionata. La probabilità condizionata di un evento E rispetto a un altro evento C, è la probabilità che si verifichi E se si verifica C, e si indica con 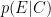
Per capire meglio cosa si intende per probabilità condizionata, torniamo all’esempio dello screening mammografico. Il problema da cui eravamo partiti sin dall’inizio era quello di determinare quale sia la probabilità che una paziente positiva alla mammografia abbia effettivamente un cancro al seno. Come abbiamo visto nell’articolo precedente questo valore si ottiene dividendo il numero di casi (o la relativa probabilità) con mammografia positiva e cancro al seno per il numero totale di casi (o la relativa probabilità) con mammografia positiva. In formula, usando i formalismi già visti:

Perché è così? Perché quello che vogliamo sapere si può tradurre in: “tra tutti i casi di mammografia positiva, qual è la percentuale di cancro al seno?” E quindi, usando i simboli che abbiamo definito sopra: “tra tutti i casi M, quanti sono anche C?” Dovremo quindi confrontare i casi M con i casi sia M che C, cioè 
Ma “tra tutti i casi di mammografia positiva, qual è la percentuale di cancro al seno?” si può riscrivere come “qual è la probabilità di un cancro a seno se la mammografia è positiva?”. Si tratta del caso classico di probabilità condizionata che, come abbiamo detto, si indica formalmente 

Uno potrebbe chiedersi perché prendersi la briga di definire una notazione apposta (e perdere tutto questo tempo per parlarne) per una cosa che, tutto sommato, sembra solo uno fra tanti possibili casi particolari di combinazioni di probabilità.
La domanda è lecita, e la risposta è che la probabilità condizionata è il concetto alla base – anche se in genere non viene esplicitato – di due modalità di ragionamento fondamentali: induzione e deduzione.
Sono le tre di notte e sono a letto, nella mia camera, e sento il rumore del temporale fuori dalla finestra chiusa. Sento i tuoni, occasionalmente il fischio del vento e lo scrosciare dell’acqua. Quindi penso: c’è un temporale.
Questa è una modalità di pensiero che è così comune per noi umani che normalmente non cerchiamo neanche di darle un nome: sento il rumore di tuoni, vento e pioggia, quindi c’è un temporale.
In realtà io non sto osservando davvero il temporale. Quelle che osservo – tuoni, rumore del vento e della pioggia – sono probabilmente conseguenze del fatto che, fuori dalla mia finestra chiusa, c’è un temporale. Quanto probabilmente? Qual è la probabilità che ci sia davvero un temporale T se sento rumori R di tuoni, pioggia e vento? Che domande, è 
Viceversa, se mi cade C il telefono dalla finestra del secondo piano, e lo vedo rimbalzare sul marciapiede, qual è la probabilità che si sia rotto R? Chiaramente sarà 
È importante capire che questi formalismi non mi stanno dicendo nulla di nuovo. La loro utilità sta nel fatto che permettono di riassumere sinteticamente e in maniera non ambigua le informazioni di cui sono già a conoscenza. Non si tratta di uno strumento magico che permette di estrarre informazioni dal nulla, ma solo di maneggiare le informazioni che già abbiamo, in maniera più precisa e sicura, per ricavarne delle risposte affidabili. Nell’articolo precedente abbiamo visto che solo il 15% dei medici a cui è stato sottoposto il problema della mammografia ha dato la risposta corretta. Il 15%! Su un problema che, affrontato nella maniera corretta, si risolve con tre somme due divisioni. Un formalismo ragionevolmente rigoroso permette di risolvere problemi simili senza neanche doverci pensare su, e senza rischiare di fare errori clamorosi.
Prima di concludere, volevo riassumere alcune proprietà fondamentali delle probabilità, che temo verranno date per scontate nell’articolo di Eliezer.
Se due eventi A e B sono indipendenti, cioè se il fatto che uno dei due si sia verificato non modifica la probabilità che si verifichi o meno l’altro, vale la seguente uguaglianza:

Che significa che la probabilità che entrambi gli eventi si verifichino è uguale al prodotto delle probabilità di ciascuno di loro. Ad esempio, se tiro due dadi, la probabilità che escano due 4 è uguale al prodotto della probabilità che il primo dia un 4, moltiplicata per la probabilità che il secondo dia un 4. Cioè: 
Se due eventi A e B sono mutuamente esclusivi, cioè se è impossibile che si verifichino entrambi contemporaneamente, vale la seguente uguaglianza:

Cioè la probabilità che si verifichi (almeno) uno dei due eventi è uguale alla somma delle probabilità individuali dei due eventi. Ad esempio, pescando una carta qualsiasi da un mazzo, la probabilità che sia picche è di 

Come caso particolare di quanto abbiamo appena detto, consideriamo un qualsiasi evento 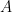




Il che significa che, per qualsiasi evento A, la somma della sua probabilità e quella del suo opposto è sempre uguale a 1. E, di conseguenza:
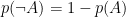
E adesso possiamo passare alla seconda parte dell’articolo di Eliezer Yudkowsky, alla fine della quale vedremo finalmente il Teorema di Bayes in tutta la sua gloria.