Questa è la seconda parte dell’articolo originale di Eliezer Yudkowsky sul teorema di Bayes. La traduzione della prima parte è qui.
[NdT. Questa seconda parte dell’articolo è molto lunga, e contiene alcuni passaggi estremamente importanti! Consiglio di leggerla con calma, magari solo un pezzo per volta, assimilando bene un concetto prima di passare all’esempio successivo. A prima vista può sembrare ripetitiva, ma ciascuno degli esempi aggiunge una tessera al mosaico complessivo, l’importante è non farsi prendere dal panico o dalla fretta! Non ti corre dietro nessuno. Non c’è un premio se arrivi in fondo più in fretta. C’è un premio, invece, se arrivi in fondo con calma, metabolizzando tutti i concetti: alla fine scoprirai di aver veramente capito come funziona il Teorema di Bayes.]
Supponiamo che un barile contenga tante piccole uova di plastica. Alcune delle uova sono colorate di rosso, altre di blu. Il 40% delle uova nel barile contiene una perla, mentre il 60% non contiene niente. Il 30% delle uova che contengono una perla sono blu e il 10% delle uova vuote sono blu. Qual è la probabilità che un uovo blu contenga una perla? Per questo esempio i calcoli sono così semplici che dovrebbe essere possibile farli a mente, e consiglio di provarci.
Ma nel caso…
Riassumiamo il problema in modo più sintetico:

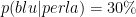

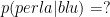

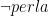

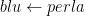
I lettori familiari con la meccanica quantistica, avranno già incontrato questa peculiarità; in meccanica quantistica, per esempio, 

L’elemento a destra è quello che conosciamo già o la premessa, l’elemento a sinistra è l’implicazione o la conclusione. Se abbiamo 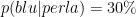

Torniamo al problema. Noi sappiamo che il 40% delle uova contengono perle e che il 60% delle uova non contengono nulla. Il 30% delle uova che contengono una perla sono blu, quindi il 12% del totale delle uova contengono una perla e sono blu. Il 10% delle uova vuote sono blu, quindi il 6% del totale delle uova sono vuote e blu. Quindi il 18% del totale delle uova sono blu, e il 12% del totale delle uova sono blu e contengono una perla. Allora la probabilità che un uovo blu contenga una perla è di 

Il programma qui sotto mostra una rappresentazione grafica di questo problema:
| Probabilità a priori: | ||||||
| Probabilità condizionali: | ||||||
| Probabilità a posteriori: |
Guardando questo grafico è più facile capire perché la risposta dipenda da tutte e tre le probabilità; è la pressione differenziale tra le due probabilità condizionali, 
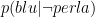
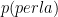
Come prima, possiamo vedere la necessità di tutte e tre le informazioni considerando dei casi estremi (potete inserirne i dati nel grafico per vedere i risultati). In un (grosso) barile nel quale solo un uovo su mille contiene una perla, sapere che un uovo è colorato di blu sposta la probabilità dallo 0.1% allo 0.3% (invece che spostarla dal 40% al 67%). Analogamente, se 999 uova su 1000 contengono una perla, sapere che un uovo è blu sposta la probabilità dal 99,9% al 99,966%; la probabilità che l’uovo non contenga una perla passa da 1/1000 a circa 1/3000. Anche quando cambiamo la probabilità a priori, la pressione differenziale delle due probabilità condizionali sposta sempre la probabilità a posteriori nella stessa direzione. Se impari che un uovo è colorato di blu, la probabilità che contenga una perla aumenta sempre – ma aumenta a partire dalla probabilità a priori, per cui dobbiamo conoscerla per calcolare la risposta finale. 0.1% aumenta fino a 0.3%, 10% aumenta fino a 25%, 40% aumenta fino a 67%, 80% aumenta fino a 92% e 99.9% aumenta fino a 99.966%. Se sei interessato a sapere come variano altre probabilità, puoi inserire la probabilità a priori nel grafico. Puoi anche spostare con il mouse la linea che separa 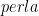
Studi sul modo di ragionare mostrano che la maggior parte dei medici mentalmente sostituiscono la probabilità originale dell’1% con la probabilità dell’80% che una donna con un cancro risulti positiva alla mammografia. In modo analogo, la maggior parte dei soggetti non familiari con il modo di ragionare bayesiano risponderebbe probabilmente che la probabilità che un uovo blu contenga una perla è del 30%, o forse del 20% (il 30% di probabilità di un positivo vero meno il 10% di un falso positivo). Anche se questa operazione mentale può sembrare una buona idea, non ha senso nel contesto della domanda effettiva. È come l’esperimento in cui chiedi a uno studente di seconda elementare: “Se 18 persone salgono su un autobus, e poi ne salgono altre 7, quanti anni ha l’autista dell’autobus?” Molti bambini rispondono: “Venticinque”. Hanno imparato a riconoscere il fatto che gli viene chiesto di usare un certo procedimento mentale, ma non l’hanno ancora collegato alla realtà. Allo stesso modo, per trovare la probabilità che una donna positiva alla mammografia abbia un cancro al seno, non ha assolutamente nessun senso sostituire la probabilità originale che una donna abbia il cancro con la probabilità che una donna con un cancro sia positiva alla mammografia. E nemmeno si può sottrarre la probabilità di un falso positivo da quella di un positivo vero. Queste operazioni sono altrettanto irrilevanti che sommare il numero dei passeggeri dell’autobus per trovare l’età dell’autista.
Continuo a enfatizzare l’idea che l’evidenza sposta la probabilità perché le ricerche mostrano che la gente usa la visualizzazione spaziale per comprendere i numeri. In particolare, ci sono prove interessanti che noi abbiamo un senso della quantità innato, localizzato nella corteccia parietale inferiore sinistra – pazienti con danni a quest’area possono perdere selettivamente la capacità di sentire che 5 è minore di 8, pur mantenendo la capacità di leggere, scrivere e così via. (Sì, davvero!) La corteccia parietale gestisce all’incirca la capacità di localizzare le cose nello spazio, per cui può essere che il senso umano dei numeri venga da una “linea numerica” o piuttosto una “linea quantitativa” innata. È per questo che suggerisco di visualizzare l’evidenza bayesiana che sposta la probabilità lungo la linea dei numeri; la mia speranza è che questo possa tradurree il ragionamento bayesiano in qualcosa che ha un senso per i meccanismi cerebrali umani innati. (Questo, in effetti è quello che è una spiegazione intuitiva). Per maggiori informazioni, vedi The Number Sense di Stanislas Dehaene.
Uno studio di Gigerenzer e Hoffrage del 1995 ha mostrato come alcuni modi di esprimere in storia i problemi sono molto più adatti a provocare un corretto ragionamento bayesiano. Il modo meno adatto è quello che usa le probabilità. Un modo leggermente migliore è quello che usa le frequenze invece delle probabilità; il problema era sempre lo stesso, ma invece di dire che l’1% delle donne ha un cancro al seno, si dirà che 1 donna su 100 ha un cancro al seno, che 80 donne con il cancro al seno ogni 100 sono positive alla mammografia, e così via. Perché una proporzione maggiore di soggetti mostra un ragionamento bayesiano corretto usando queste parole? Probabilmente perché dire “1 donna su 100” ti spinge a visualizzare concretamente X donne con un cancro, il che porta a visualizzare X donne con cancro e positive alla mammografia, eccetera.
La presentazione più efficiente trovata finora è quella basata sulle cosiddette frequenze naturali – dire che 40 uova su 100 contengono perle, 12 uova contenenti perle su 40 sono blu e 6 uova vuote su 60 sono blu. Una presentazione per frequenze naturali è una in cui l’informazione sulla probabilità a priori è unita alla presentazione delle probabilità condizionali. Se tu stessi imparando le probabilità condizionali delle uova mediante l’esperienza diretta, troveresti – aprendo cento uova – circa 40 uova contenenti una perla delle quali 12 uova blu, e 60 uova vuote delle quali circa 6 sarebbero blu. Nell’apprendere queste probabilità condizionali, vedresti esempi di uova blu che contengono perle il doppio più spesso di uova blu vuote.
Può sembrare che presentare il problema in questo modo sia un po’ “barare”, e se questo fosse un problema in un libro di matematica probabilmente sarebbe barare. Tuttavia, se stiamo parlando di medici reali, noi vogliamo barare; vogliamo che il medico ottenga la conclusione corretta il più facilmente possibile. L’ovvia mossa successiva sarebbe di presentare tutte le statistiche mediche in termini di frequenze naturali. Sfortunatamente, anche se le frequenze naturali sono un passo nella direzione giusta, probabilmente non sono sufficienti. Quando i problemi sono posti in termini di frequenze naturali, la frazione di persone che usa il ragionamento bayesiano aumenta fino a circa metà. Un grosso miglioramento, ma non abbastanza se stiamo parlando di veri medici e veri pazienti.
Una presentazione del problema in frequenze naturali potrebbe essere visualizzato così:
| Probabilità a priori: | ||||||
| Probabilità condizionali: | ||||||
| Probabilità a posteriori: |
Nella visualizzazione di frequenze, è il contrasto selettivo tra le due probabilità condizionali che modifica la proporzione di uova che contengono una perla. La barra inferiore è più corta della superiore, come il numero di uova blu è inferiore al numero totale di uova. Il grafico di probabilità mostrato prima è in realtà lo stesso grafico di frequenza con la barra inferiore “rinormalizzata”, cioè allungata fino alla stessa lunghezza della barra superiore. Nel grafico delle frequenze, puoi modificare le probabilità condizionali trascinando i bordi destro e sinistro del grafico. (Ad esempio, per modificare la probabilità condizionale
Nella visualizzazione di probabilità, puoi vedere che quando le probabilità condizionali sono uguali tra loro non c’è pressione differenziale – le frecce sono della stessa lunghezza – e quindi la probabilità a priori non si sposta tra la barra superiore e l’inferiore. Ma la barra inferiore nella visualizzazione di probabilità è solo una versione rinormalizzata (allargata) della barra inferiore in visualizzazione di frequenze, e la visualizzazione di frequenze mostra perché la probabilità non cambia se le due probabilità condizionali sono uguali. Ecco un caso in cui la proporzione a priori di perle rimane del 40%, e la proporzione di uova colorate di blu resta al 30%, ma il numero di uova vuote blu è anche del 30%:
| Probabilità a priori: | ||||||
| Probabilità condizionali: | ||||||
| Probabilità a posteriori: |
Se riduciamo due forme dello stesso fattore, le proporzioni relative rimangono uguali a prima. Se riduciamo la parte di sinistra della barra superiore della stessa proporzione di quella di destra, la barra inferiore manterrà le stesse proporzioni della barra superiore – sarà solo più piccola. Se le due probabilità condizionali sono uguali, imparare che un uovo è blu non modifica la probabilità che l’uovo contenga una perla – per la stessa ragione per cui triangoli simili hanno angoli identici; le figure geometriche non cambiano forma quando le rimpiccioliamo di un fattore costante.
In questo caso potremmo dire semplicemente che il 30% delle uova sono blu, dato che la probabilità che un uovo sia blu è indipendente dal fatto che contenga una perla. Applicare un “test” statisticamente indipendente dalla sua condizione, riduce semplicemente il campione. In questo caso, richiedere che l’uovo sia blu non riduce il gruppo delle⋂ né più né meno di quanto riduca il gruppo delle uova senza perla. Riduce semplicemente il numero di uova nel campione.
E questo è come appare il problema originale sotto forma di grafico. L’1% delle donne hanno un cancro, l’80% di queste risultano positive alla mammografia e il 9.6% di donne senza cancro risultano anche loro positive alla mammografia.
| Probabilità a priori: | ||||||
| Probabilità condizionali: | ||||||
| Probabilità a posteriori: |
Come ora è chiaramente visibile, la mammografia non aumenta la probabilità di che una donna con esito positivo abbia il cancro aumentando il numero di donne con cancro – ovviamente no; se la mammografia aumentasse il numero di casi di cancro nessuno farebbe il test! Tuttavia, richiedere una mammografia positiva è un test di appartenenza che elimina molte più donne senza cancro che donne con cancro. Il numero di donne senza cancro diminuisce di un fattore maggiore di dieci, da 9.900 a 950, mentre il numero di donne con cancro diminuisce solo da 100 a 80. Così la proporzione di 80 su 1.030 è molto maggiore della proporzione di 100 su 10,000. Nel grafico, il settore di sinistra (che rappresenta le donne con cancro) è piccolo, ma la mammografia proietta quasi tutto questo settore sulla barra inferiore. Il settore destro (che rappresenta le donne senza cancro) è grande, ma la mammografia proietta una frazione molto più piccola di questo settore sulla barra inferiore. Ci sono, è vero, meno donne con cancro e positive alla mammografia che donne con cancro – obbedendo alla legge delle probabilità che richiede che 
Supponiamo che ci sia ancora un’altra variante della mammografia, mammografia@, che si comporta come segue. L’1% delle donne in una certa popolazione hanno un cancro al seno. Come la mammografia ordinaria, la mammografia@ risulta positiva nel 9.6% dei casi per donne senza un cancro al seno. Tuttavia, la mammografia@ risulta positiva lo 0% delle volte (diciamo, una volta su un miliardo) per le donne con cancro. Il grafico di questo scenario risulta così:
| Probabilità a priori: | ||||||
| Probabilità condizionali: | ||||||
| Probabilità a posteriori: |
Cos’è che fa davvero questo esame? Se una paziente viene da voi con un risultato positivo alla mammografia@, cosa le dite?
“Congratulazioni, sei nel ristretto 9.5% della popolazione per il quale questo test stabilisce in maniera definitiva che non hai un cancro.”
Mammografia@ non è un test per il cancro; è un test per individuare le pazienti sane! Poche donne senza cancro al seno risultano positive alla mammografia@, ma solo donne senza cancro al seno. Non molto del settore di destra viene proiettato sulla barra inferiore, ma niente del settore di sinistra viene proiettato. Così un risultato positivo alla mammografia@ significa che la paziente certamente non ha un cancro.
Quello che rende la mammografia un indicatore positivo per il cancro al seno, non è il fatto che qualcuno ha chiamato “positivo” il risultato, ma piuttosto il fatto che c’è una specifica relazione bayesiana tra i risultati dell’esame e la presenza di un cancro. Potremmo chiamare gli stessi risultati “positivo” e “negativo” o “blu” e “rosso” o “James Rutherford”, o non dargli nessun nome, e i risultati dell’esame continuerebbero a spostare la probabilità esattamente allo stesso modo. Per minimizzare la confusione, un risultato che sposta la probabilità di cancro verso l’alto dovrebbe essere chiamato “positivo”, un risultato che la sposta verso il basso “negativo”. Se il risultato dell’esame non è statisticamente correlato alla presenza o assenza di cancro – se le due probabilità condizionali sono uguali – allora non dovremmo proprio chiamarlo un “esame del cancro”! Il significato dell’esame è determinato dalle due probabilità condizionali; qualunque nome venga dato ai risultati è solo una comoda etichetta.
| Probabilità a priori: | ||||||
| Probabilità condizionali: | ||||||
| Probabilità a posteriori: |
La barra inferiore del grafico della mammografia@ è piccola; mammografia@ è un esame che solo raramente è utile. O meglio, l’esame fornisce solo raramente una forte evidenza, mentre nella maggior parte dei casi fornisce solo un’evidenza debole. Un risultato negativo alla mammografia@ sposta la probabilità – ma non la sposta di molto. Clicca il bottone “risultato” nell’angolo in basso a sinistra del grafico per vedere cosa implica un risultato negativo alla mammografia@. Si può intuire che, siccome l’esame avrebbe potuto dare un risultato positivo su una paziente sana, ma non l’ha fatto, il fatto che l’esame non abbia dato risultato positivo deve significare che la paziente ha una probabilità più alta di avere un cancro – che la sua probabilità di avere un cancro dev’essere spostata in alto dal risultato negativo nel suo “test di salute”.
L’intuizione è corretta! La somma dei gruppi con risultati negativi e positivi deve sempre essere uguale al gruppo di tutte le pazienti. Se il gruppo delle pazienti con risultato positivo ha “più della sua giusta quota” di donne senza cancro al seno, ci dev’essere una proporzione almeno leggermente più alta di donne con cancro nel gruppo dei risultati negativi. Un risultato positivo è un’evidenza rara ma forte in una direzione, mentre un risultato negativo è un’evidenza comune ma molto debole nella direzione opposta. Potremmo chiamarla la Legge della Conservazione delle Probabilità – non è un termine standard, ma la regola di conservazione è reale. Se prendiamo la probabilità modificata di cancro al seno dopo un risultato positivo, moltiplicata per la probabilità di un risultato positivo, e la sommiamo alla probabilità modificata di cancro al seno dopo un risultato negativo, moltiplicata per la probabilità di un risultato negativo, il risultato dovrà sempre essere uguale alla probabilità a priori. Se non conosciamo ancora il risultato dell’esame, la probabilità modificata attesa dopo il risultato dell’esame – considerando entrambi i possibili risultati – dovrà sempre essere uguale alla probabilità a priori.
Nella mammografia ordinaria, ci aspettiamo che l’esame risulti positivo il 10.3% delle volte – 80 donne positive con cancro più 950 positive senza cancro danno 1.030 donne con risultato positivo. Viceversa, la mammografia dovrebbe risultare negativa l’89.7% delle volte: 100% – 10.3% = 89.7%. Un risultato positivo sposta la probabilità da 1% a 7.8%, mentre un risultato negativo la sposta da 1% a 0.22%. Quindi:

come previsto.
Perché “come previsto”? Diamo un’occhiata alle quantità in gioco:
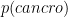 : : |
0.01 | Gruppo 1: 100 donne con cancro al seno | |
 : : |
0.99 | Gruppo 2: 9900 donne senza cancro al seno | |
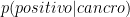 : : |
80.0% | 80% di donne con cancro al seno sono positive alla mammografia | |
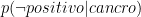 : : |
20.0% | 20% di donne con cancro al seno sono negative alla mammografia | |
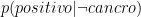 : : |
9.6% | 9.6% di donne senza cancro al seno sono positive alla mammografia | |
 : : |
90.4% | 90.4% di donne senza cancro al seno sono negative alla mammografia | |
 : : |
0.008 | Gruppo A: 80 donne con cancro al seno e mammografia positiva | |
 : : |
0.002 | Gruppo B: 20 donne con cancro al seno e mammografia negativa | |
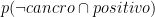 : : |
0.095 | Gruppo C: 950 donne senza cancro al seno e mammografia positiva | |
 : : |
0.895 | Gruppo D: 8950 donne senza cancro al seno e mammografia negativa | |
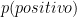 : : |
0.103 | 1030 donne con mammografia positiva | |
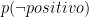 : : |
0.897 | 8970 donne con mammografia negativa | |
 : : |
7.80% | Probabilità di avere il cancro al seno se la mammografia è positiva: 7.8% | |
 : : |
92.20% | Probabilità di essere sana se la mammografia è positiva: 92.2% | |
 : : |
0.22% | Probabilità di avere il cancro al seno se la mammografia è negativa: 0.22% | |
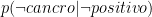 : : |
99.78% | Probabilità di essere sana se la mammografia è negativa: 99.78% |
Uno degli errori comuni nell’applicare il ragionamento bayesiano, consiste nel mescolare alcune o tutte queste quantità – che, come si può vedere, sono tutte numericamente differenti e hanno significati diversi. 
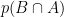
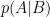

Per familiarizzarci con tutte queste quantità e con le relazioni tra esse, giocheremo a “segui i gradi di libertà”. Per esempio, le due quantità 



Anche
E che dire di 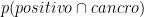
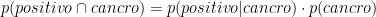
Questa uguaglianza riduce di uno i gradi di libertà. Se conosciamo la frazione di pazienti con cancro, e la probabilità che una paziente con cancro sia positiva alla mammografia, possiamo dedurre la percentuale di pazienti che hanno un cancro e sono positive alla mammografia con una moltiplicazione. Si può riconoscere questa operazione dal grafico: è nella proiezione della barra superiore sull’inferiore.
| Probabilità a priori: | ||||||
| Probabilità condizionali: | ||||||
| Probabilità a posteriori: |
In modo analogo, se sappiamo il numero di pazienti con cancro al seno e positive alla mammografia, e anche il numero totale di pazienti con cancro al seno, possiamo stimare la possibilità che una donna con cancro al seno sia positiva alla mammografia dividendo: 
Proviamo con 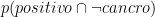
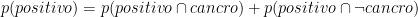
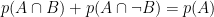

Infine cosa succede con 
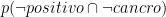

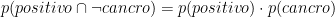

Questa equazione impegna un grado di libertà, lasciando tre gradi di libertà alle quattro quantità. Se conosciamo le frazioni di donne nei gruppi A, B e D, possiamo calcolare la frazione di donne nel gruppo C.
Dati i quattro gruppi A, B, C e D, è immediato calcolare tutto il resto: 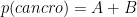
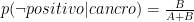
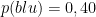
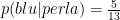
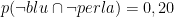
Definendolo a parole:
Supponiamo di avere un barile che contiene una quantità di uova di plastica. Alcune uova contengono una perla, le altre sono vuote. Alcune uova sono blu, le altre rosse. Supponiamo che il 40% delle uova sia blu.
delle uova contenenti una perla sono blu e 20% delle uova sono vuote e rosse. Qual è la probabilità che un uovo blu contenga una perla?
Provaci – ti assicuro che è possibile.
Probabilmente non bisognerebbe risolvere questo problema con una calcolatrice javascript; io ho usato una console Python. (In teoria dovrebbero essere sufficienti carta e matita, ma non conosco nessuno che possieda una matita, e quindi non ho potuto provare di persona).
Come controllo sui tuoi calcoli, la quantità (non particolarmente significativa) 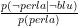
Se puoi risolvere questo problema, allora quando torneremo sulla Conservazione della Probabilità, sembrerà assolutamente ovvia. Naturalmente la probabilità rivista media, dopo il test, dev’essere uguale alla probabilità a priori. Naturalmente un’evidenza rara ma forte in una direzione dev’essere controbilanciata da un’evidenza comune ma debole nella direzione opposta.
Perché:
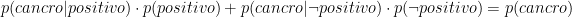
In termini dei quattro gruppi:
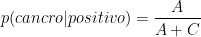


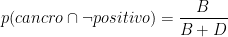

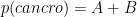
Torniamo al barile originale di uova – il 40% delle uova contiene una perla, il 30% delle uova che contengono una perla sono blu e il 10% delle uova vuote sono blu. Il grafico per questo problema è il seguente:
| Probabilità a priori: | ||||||
| Probabilità condizionali: | ||||||
| Probabilità a posteriori: |
Cosa succede alla probabilità rivista,
Se hai immaginato che la probabilità rivista rimane la stessa, perché la barra inferiore raddoppia di lunghezza ma mantiene le stesse proporzioni, congratulazioni! Prenditi un attimo per pensare quanto sei arrivato avanti. Guardando un problema come questo
L’1% delle donne hanno un cancro al seno. L’80% delle donne con cancro al seno sono positive alla mammografia. Il 9.6% delle donne senza cancro al seno sono positive alla mammografia. Se una donna è positiva alla mammografia, qual è la probabilità che abbia un cancro al seno?
la grande maggioranza degli interrogati immagina che circa il 70-80% delle donne positive alla mammografia abbiano un cancro al seno. Ora, guardando un problema come questo
Supponiamo che ci siano due barili che contengono tante piccole uova di plastica. In entrambi i barili, alcune uova sono blu e le altre sono rosse. In entrambi i barili, il 40% delle uova contiene una perla e le altre sono vuote. Nel primo barile il 30% delle uova che contengono una perla sono blu e il 10% delle uova vuote sono blu. Nel secondo barile il 60% delle uova che contengono una perla sono blu e il 20% delle uova vuote sono blu. Preferiresti prendere un uovo blu dal primo barile o dal secondo?
puoi vedere che è intuitivamente ovvio che la probabilità che un uovo blu contenga una perla è la stessa per entrambi i barili. Immagina quanto sarebbe stato difficile arrivarci usando il vecchio modo di pensare!
È intuitivamente ovvio, ma come dimostrarlo? Supponiamo di chiamare P la probabilità a priori che un uovo contenga una perla, di chiamare M la prima probabilità condizionale (che un uovo che contiene una perla sia blu) e N la seconda probabilità condizionale (che un uovo vuoto sia blu). Supponiamo che sia M che N siano aumentati o diminuiti di un fattore arbitrario X – per esempio, nel caso sopra, sono entrambi aumentate di un fattore 2. La probabilità rivista che un uovo blu contenga una perla, resta la stessa?
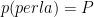
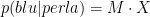
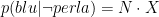
Da queste quantità, otteniamo i quattro gruppi:
- Gruppo A:
- Gruppo B:
- Gruppo C:
- Gruppo D:

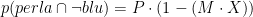

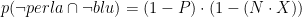
La proporzione di uovo che contengono una perla e sono blu, nel gruppo di tutte le uova blu, è quindi il rapporto tra il gruppo A e il gruppo (A+C), che è uguale a 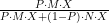
La probabilità che un test dia un positivo vero divisa per la probabilità che lo stesso test dia un falso positivo è noto come il coefficiente di verosimiglianza del test. Il coefficiente di verosimiglianza di un esame medico, è sufficiente a riassumere tutto quello che c’è di utile da sapere sull’utilità del test?
No, non è sufficiente! Il coefficiente di verosimiglianza riassume tutto quello che c’è da sapere sul significato di un risultato positivo, ma non specifica né il significato di un risultato negativo, né la frequenza con cui il test è utile. Se esaminiamo le formule sopra, mentre 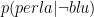
Supponiamo che ci siano due barili che contengono tante piccole uova di plastica. In entrambi i barili, alcune uova sono blu e le altre sono rosse. In entrambi i barili, il 40% delle uova contiene una perla e le altre sono vuote. Nel primo barile il 30% delle uova che contengono una perla sono blu e il 10% delle uova vuote sono blu. Nel secondo barile il 90% delle uova che contengono una perla sono blu e il 30% delle uova vuote sono blu. Preferiresti prendere un uovo blu dal primo barile o dal secondo? Preferiresti prendere un uovo rosso dal primo barile o dal secondo?
Per la prima domanda, la risposta è che non ha importanza se prendiamo l’uovo dal primo o dal secondo barile. Per la seconda domanda, tuttavia, le probabilità cambiano – nel primo barile il 34% delle uova rosse contengono una perla, mentre nel secondo barile l’8.7% delle uova rosse contengono una perla! Quindi dovremmo preferire un uovo rosso dal primo barile. Nel primo barile il 70% delle⋂ sono rosse e il 90% delle uova vuote sono rosse. Nel secondo barile il 10% delle⋂ sono rosse e il 70% delle uova vuote sono rosse.
Cos’è successo? Cominciamo con il notare che, controintuitivamente, 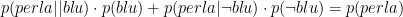
| Probabilità a priori: | ||||||
| Probabilità condizionali: | ||||||
| Probabilità a posteriori: |
Torniamo all’esempio dell’esame medico. Il coefficiente di verosimiglianza di un esame medico – il numero di positivi veri diviso per il numero di falsi positivi – ci dice tutto quello che c’è da sapere sul significato di un risultato positivo. Ma non ci dice niente sul significato di un risultato negativo, e non ci dice quanto spesso l’esame sia utile. Per esempio, una mammografia che riconosce l’80% delle pazienti con cancro al seno e dà un 9.6% di falsi positivi su pazienti sane, ha lo stesso coefficiente di verosimiglianza di un esame con l’8% di positivi veri e lo 0,96% di falsi positivi. Anche se questi due esami hanno lo stesso coefficiente di verosimiglianza, il primo è più utile in ogni senso – riconosce più spesso la malattia e un risultato negativo è un’evidenza più forte di salute.
Il coefficiente di verosimiglianza per un risultato positivo riassume la pressione differenziale delle due probabilità condizionali per un risultato positivo, e quindi riassume quanto un risultato positivo sposterà la probabilità a priori. Prendiamo un grafico di probabilità, come questo:
| Probabilità a priori: | ||||||
| Probabilità condizionali: | ||||||
| Probabilità a posteriori: |
Il coefficiente di verosimiglianza della mammografia è quello che determina l’inclinazione della linea. Se la probabilità a priori è dell’1%, conoscendo solo il coefficiente di verosimiglianza è possibile calcolare la probabilità a posteriori dopo un risultato positivo.
Ma, come puoi vedere dal grafico delle frequenze, il coefficiente di verosimiglianza non racconta la storia completa – nel grafico delle frequenze le proporzioni della barra inferiore possono restare fisse mentre cambiano le dimensioni della barra. 




È ovvio che il coefficiente di verosimiglianza non può raccontarci tutta la storia, il coefficiente di verosimiglianza e la probabilità a priori, insieme, sono solo due numeri, mentre il problema ha tre gradi di libertà.
Supponiamo di applicare in successione due esami per il cancro al seno – diciamo una mammografia standard e un altro esame che sia indipendente dalla mammografia. Dato che non conosco un test del genere che sia indipendente dalla mammografia, ne inventerò uno per gli scopi di questo problema, e lo chiamerò il Test di Divisione di Tams-Braylor, che verifica se qualche cellula si divide più rapidamente delle altre cellule. Supponiamo che il Tams-Braylor dia un positivo vero per il 90% delle pazienti con cancro al seno e un falso positivo per il 5% delle pazienti senza cancro. Diciamo che la prevalenza a priori del cancro al seno sia dell’1%. Se una paziente risulta positiva alla mammografia e al Tams-Braylor, qual è al probabilità modificata che abbia un cancro al seno?
Un modo di risolvere questo problema sarebbe di prendere la probabilità modificata da una mammografia positiva, che abbiamo già calcolato essere il 7.8%, e inserirla nell’esame Tams-Braylor come probabilità a priori. Se facciamo così, vediamo che il risultato è circa il 60%.
Ma qui abbiamo supposto di avere prima il risultato positivo alla mammografia, e poi il risultato positivo al test Tams-Braylor. Cosa succede se la paziente ottiene un risultato positivo al Tams-Braylor, seguito da un positivo alla mammografia? Intuitivamente sembra che non dovrebbe avere importanza. I calcoli lo confermano?
Prima effettuiamo l’esame Tams-Braylor a una donna con una proprietà a priori dell’1% di cancro al seno.
Poi eseguiamo una mammografia, che dà un 80% di positivi veri e un 9.6% di falsi positivi, e anche questa risulta positiva.
E guarda! Il risultato è ancora il 60%. (Se non è esattamente uguale è a causa degli arrotondamenti – puoi usare un calcolatore più preciso, o fare i conti delle frazioni a mano, e i numeri saranno esattamente uguali).
La dimostrazione algebrica che le due strategie sono equivalenti è lasciata come esercizio per il lettore. Visivamente, immagina che la barra inferiore del grafico di frequenze per la mammografia proietti un’ulteriore barra usando le probabilità del test Tams-Braylor, e che questa terza barra risulti uguale indipendentemente dall’ordine in cui le probabilità condizionali sono proiettate.
Potremmo anche ragionare che poiché i due esami sono indipendenti, la probabilità che una donna con un cancro al seno sia positiva alla mammografia e al test Tams-Braylor è del 90% * 80% = 72%. E la probabilità che una donna senza cancro ottenga un falso positivo sia alla mammografia che al Tams-Braylor è del 5% * 9.6% = 0.48%. Così se consideriamo l’insieme come un unico esame con coefficiente di verosimiglianza di 72%/0.48%, e lo applichiamo a una donna con l’1% di probabilità a priori di avere un cancro:
…troviamo ancora una volta che il risultato è 60%.
Supponiamo che la prevalenza a priori del cancro al seno in una popolazione sia dell’1%. Supponiamo inoltre che noi, come medici, abbiamo a disposizione un repertorio di tre esami indipendenti. Il nostro primo esame, esame A, la mammografia, ha un coefficiente di verosimiglianza di 
Ecco un trucchetto per semplificare i conti. Le la prevalenza a priori del cancro al seno in una popolazione è dell’1%, allora 1 donna su 100 ha un cancro al seno, e 99 su 100 non ce l’hanno. Quindi, se riscriviamo la probabilità dell’1% come un rapporto, le possibilità sono:
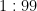
E i coefficienti di verosimiglianza dei tre esami A, B e C sono:
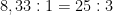
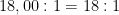

Il rapporto di donne con cancro e donne senza cancro, dopo aver avuto tutti e tre gli esami positivi, sono :

Per trovare la probabilità dal rapporto, scriviamo:
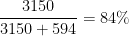
Questo funziona sempre, indipendentemente da come sono scritti i rapporti; cioè 8,33:1 è esattamente la stessa cosa di 25:3 o 75:9. Non ha importanza in quale ordine vengono effettuati gli esami, o in quale ordine vengono calcolati i risultati. La dimostrazione è lasciata come esercizio per il lettore.
E. T. Jaynes, in “Probability Theory With Applications in Science and Engineering”, suggerisce che credibilità ed evidenza dovrebbero essere misurati in decibel.
Decibel?
I decibel sono usati per misurare differenze di intensità esponenziali. Per esempio, se il suono di un clacson da macchina porta 10.000 volte più energia (per metro quadro per secondo) di una sveglia, il clacson sarà 40 decibel più forte della sveglia. Il suono di un uccello che canta potrebbe portare 1.000 volte meno energia della sveglia, e quindi essere 30 decibel più debole. Per calcolare il numero dei decibel, si prende il logaritmo in base 10 e si moltiplica per 10.

o
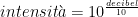
Supponiamo di partire con una probabilità dell’1% che una donna abbia un cancro al seno, corrispondente a un rapporto di 1:99. E poi somministriamo tre esami con coefficienti di verosimiglianza di 25:3, 18:1 e 7:2. Potremmo moltiplicare questi numeri… oppure potremmo sommare i loro logaritmi:
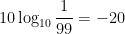



Partiamo con una forte improbabilità che una donna abbia un cancro al seno – il livello di credibilità è a -20 decibel. Poi arrivano i risultati di tre esami, corrispondenti a 9, 13 e 5 decibel di evidenza. Questo aumenta il livello di credibilità di un totale di 27 decibel, cioè porta il livello iniziale di -20 a una credibilità a posteriori di 7 decibel. Così il rapporto sale da 1:99 a 5:1, e la probabilità passa da 1% a circa 83%.
Davanti a te c’è uno zainetto contenente 1000 fiche da poker. Inizialmente gli zainetti erano due, uno contenente 700 fiche rosse e 300 blu, l’altro con 300 fiche rosse e 700 blu. Ho tirato una moneta per determinare quale zainetto prendere, per cui la probabilità che quello davanti a te sia lo zainetto “rosso” è del 50%. Ora tu estrai a caso delle fiche, una per volta, e le rimetti dentro dopo averle guardate. In 12 tentativi trovi 8 rossi e 4 blu. Qual è la probabilità che questo sia lo zainetto a dominanza rossa?
Prova a fare il conto a mente. Non importa che sia il risultato esatto, basterebbe un’approssimazione grossolana. Quando sei pronto, prosegui.
Secondo uno studio effettuato nel 1966 da Lawrence Phillips e Ward Edwards, la maggior parte risponde a questo problema con una stima nell’intervallo dal 70% all’80%. Hai previsto una probabilità sostanzialmente più alta di così? In tal caso, congratulazioni – Ward Edwards scrive che molto raramente una persona risponde correttamente, anche con persone relativamente familiari al ragionamento bayesiano. La risposta corretta è 97%.
Il coefficiente di verosimiglianza per il risultato “fiche rossa” è di 7/3, mentre il coefficiente di verosimiglianza per il risultato “fiche blu” è di 7/3. Quindi una fiche blu è esattamente la stessa quantità di evidenza di una fiche rossa, ma nella direzione opposta – una fiche rossa corrisponde a 3,6 decibel di evidenza per lo zainetto rosso, mentre una fiche blu è -3.6 decibel di evidenza. Se estrai una fiche rossa e una blu, si annullano a vicenda. Quindi il rapporto tra le estrazioni rosse e quelle blu non ha importanza; conta solo l’eccesso di rossi sopra i blu. In dodici estrazioni c’erano otto rossi e quattro blu; quindi quattro fiche rosse in più rispetto alle blu. Quindi le possibilità a posteriori saranno:

che è circa 30:1, cioè circa il 97%.
La credibilità a priori partiva a 0 decibel e c’è all’incirca un totale di 14 decibel di evidenza, e infatti questo corrisponde a possibilità di circa 25:1 cioè circa il 96%. Di nuovo, c’è qualche imprecisione dovuta agli arrotondamenti, ma se avessimo fatto i calcoli esatti i risultati sarebbero stati identici.
Adesso possiamo vedere intuitivamente che il problema degli zainetti avrebbe avuto esattamente la stessa risposta, ottenuta in esattamente lo stesso modo, se avessimo estratto sedici fiche e ne fossero risultate dieci rosse e sei blu.
Sei un meccanico che ripara sarchiaponi. Quando un sarchiapone si rompe, il 30% delle volte è dovuto a un tubo intasato, Se il tubo di un sarchiapone è intasato, c’è il 45% di probabilità che scuotendo il sarchiapone faccia scintille. Se il tubo di un sarchiapone non è intasato c’è solo il 5% di probabilità che scuotendolo faccia scintille. Un cliente ti porta un sarchiapone difettoso. Lo scuoti e vedi che fa scintille. Qual è la probabilità che un sarchiapone che fa scintille abbia il tubo intasato?
Qual è la sequenza di operazioni aritmetiche che hai fatto per risolvere questo problema
(45% * 30%) / (45% * 30% + 5% * 70%)
| Probabilità a priori: | ||||||
| Probabilità condizionali: | ||||||
| Probabilità a posteriori: |
Allo stesso modo, per calcolare la probabilità che una donna positiva alla mammografia abbia il cancro al seno, abbiamo calcolato:

che equivale a
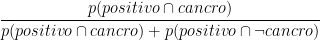
che equivale a

che equivale a

La forma generale di questo calcolo è nota come Teorema di Bayes o Regola di Bayes:

Dato un fenomeno A che vogliamo investigare, e un’osservazione X che è evidenza di A – per esempio, nell’esempio precedente, A è il cancro al seno e X una mammografia positiva – il Teorema di Bayes ci dice come dobbiamo aggiornare la nostra probabilità di A sulla base della nuova evidenza X.
| Probabilità a priori: | ||||||
| Probabilità condizionali: | ||||||
| Probabilità a posteriori: |
A questo punto il Teorema di Bayes può sembrare banalmente ovvio o addirittura tautologico, pittosto che qualcosa di nuovo ed eccitante. Se è così, questa introduzione ha avuto un completo successo.