Probabilità
Tutti sappiamo cosa significa probabilità, vero?
È così semplice: la probabilità che tirando un dado esca un numero pari è del 50%. Cioè la probabilità è quel numerino che mi dice quanto è probabile che…
Ooops.
Se vogliamo evitare la trappola del ragionamento circolare, dobbiamo definire la parola “probabilità” evitando di usare la parola stessa e tutti i suoi sinonimi. E la cosa non è facile, sembra che “probabilità” (o anche “probabile”) sia una di quelle parole che tutti comprendono ma nessuno sa definire; un po’ come “tempo” (la migliore definizione di “tempo” che io conosca è “quella grandezza misurata dagli orologi”. Non sto scherzando).
In realtà esistono un certo numero di definizioni per il concetto di probabilità, e ciascuna di loro cattura alcuni degli aspetti impliciti nel significato comune del termine, ma nessuna riesce a coglierlo completamente. Quando ci accorgiamo di un fenomeno del genere, si dovrebbe accendere una piccola spia rossa dentro la nostra testa che dice: “ATTENZIONE! Concetto mal definito”. Quando non riusciamo a trovare una spiegazione semplice, e neanche una complicata, per un concetto che il nostro cervello considera semplice, in genere è colpa del fatto che non si tratta affatto di un concetto semplice, ma di una parola troppo generica che comprende al suo interno diversi concetti simili ma differenti tra loro.
Nel caso della parola “probabilità” ci limiteremo ad esaminare le due definizioni più diffuse: quella frequentista e quella bayesiana.
La definizione frequentista di probabilità è, nella sua forma originale, ingannevolmente semplice: se voglio sapere qual è la probabilità che il tiro di un dado dia come risultato 6, faccio un gran numero di tiri contando quante volte esce 6 (successo) e quante volte un altro numero (fallimento). Se chiamiamo “S” il numero dei successi (è uscito 6), “F” il numero di fallimenti (è uscito un numero diverso da 6) e “T” il numero totale di lanci (S + F), si definisce frequenza dei successi il rapporto 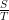
La probabilità frequentista è definita come il numero P a cui tende la frequenza dei successi all’aumentare di T e cioè, in altre parole, equivale alla frequenza dei successi su un numero abbastanza grande di lanci. Formalmente:

Questa sembra (ed è) un’ottima definizione: abbiamo evitato completamente il ragionamento circolare della definizione intuitiva e abbiamo uno strumento operativamente utilizzabile. Se voglio sapere qual è la probabilità che tirando un dado esca 6, devo solo effettuare un numero infinito di tiri e contare le volte che esce 6… No, d’accordo, sto esagerando. Se so che il dado non è truccato, cioè che non ha preferenze per una faccia rispetto alle altre, posso calcolare la probabilità P di cui sopra senza bisogno di provare all’infinito.
D’altra parte, come faccio a sapere che il dado non ha una preferenza per il 3 se non provando un numero sufficiente di volte?
Inoltre, la definizione frequentista di probabilità ha un altro grave problema, un’incapacità di giustificare una parte di quella che noi consideriamo intuitivamente “probabilità”. Lo vediamo con un altro esempio.
Qual è la probabilità P che domani piova?
Con la domanda posta in questi termini, la definizione frequentista non ci permette di dare un senso a P: è evidente che non posso provare un numero sufficiente di versioni diverse di domani per vedere qual è la frequenza dei domani in cui piove.
Naturalmente, visto che oggi è il 27 di aprile, domani sarà il 28 di aprile. Posso prendere la serie storica del clima nella mia località e contare quante volte ha piovuto a casa mia nella giornata del 28 aprile negli ultimi 100 anni. Questo numero diviso per 100 mi darà la frequenza di 28 aprile piovosi negli ultimi cento anni e sarà certamente una buona approssimazione della probabilità P richiesta.
Ma nel fare questo abbiamo aggirato la definizione: non stiamo davvero analizzando 100 versioni diverse di domani, stiamo solo analizzando 100 versioni diverse del 28 aprile. Non è la stessa cosa.
Non è la stessa cosa perché domani è martedì 28 aprile, quindi basandomi sulla stessa logica avrei potuto prendere la frequenza dei martedì piovosi nelle ultime 100 settimane, e questa frequenza è presumibilmente molto diversa da quella calcolata prima.
Ma, mi farà notare qualcuno, è stupido pensare che la piovosità dipenda dal giorno della settimana, mentre tutti sanno che dipende dalla stagione. Prendere gli ultimi 100 martedì passati non ha nessuna giustificazione, mentre prendere i 28 aprile degli 100 anni ha senso, perché in questo modo confrontiamo dati relativi allo stesso punto nel ciclo stagionale.
E questo è sicuramente vero. Ma se posso tranquillamente ammettere che la prima stima di probabilità fosse migliore della seconda, non sono disposto a sostenere che corrisponda veramente alla probabilità P.
Ad esempio, la stima sugli ultimi 100 anni non tiene conto delle variazioni a lungo termine del clima, del ciclo dell’attività solare, del fatto che domani magari ci sarà un’eclissi di sole.
Per quanto io possa scegliere un campione di giorni simili a domani, non saranno mai 100 copie di domani. Quindi la definizione frequentista, applicata alla probabilità di eventi singoli, è utilizzabile solo se mediata dalla scelta di un campione adeguato, cioè un campione formato da eventi in cui la probabilità di successo è uguale a quella dell’evento singolo in esame.
Nel nostro caso, dovremo scegliere un campione di giorni (nel passato, e sui quali abbiamo dati storici sulla piovosità) che abbiano il più possibile la stessa probabilità di essere piovosi di domani martedì 28 aprile 2015.
… la stessa probabilità … ?
E questo è il vero problema: la definizione frequentista di probabilità di eventi singoli è di nuovo una definizione circolare; in si basa su un campione che dev’essere scelto sulla base della probabilità stessa che sta cercando di definire.
Lo stesso esempio del dado, che ci sembrava così obiettivamente esatto, nascondeva in realtà lo stesso problema: il metodo con cui abbiamo ricavato la probabilità che tirando il dado esca 6, 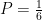
Mettiamo per il momento da parte la definizione frequentista e passiamo alla definizione bayesiana di probabilità.
La probabilità di un evento, in senso bayesiano, è una misura della mia aspettativa del fatto che quell’evento si verifichi o meno.
Questa aspettativa viene rappresentata con un numero compreso tra 0 e 1, dove 1 corrisponde alla certezza che l’evento si verifichi, mentre al contrario 0 indica la certezza che l’evento non si verifichi affatto.
Nei casi intermedi – tra l’assolutamente certo e l’assolutamente impossibile – assegneremo valori di probabilità intermedi, maggiori quando l’aspettativa è più alta, minori quando è più bassa.
Perché la definizione sia coerente, e omogenea con la definizione frequentista – cioè che riporti gli stessi numeri in quei casi in cui sono applicabili entrambe – l’assegnazione di questi valori di probabilità deve rispettare certe regole, tra le quali vediamo adesso le più importanti:
Nel caso di due eventi mutuamente esclusivi, cioè eventi che non possono avvenire contemporaneamente (ad esempio, che un tiro di dado dia come risultato 3 oppure 5: può capitare l’uno, l’altro o nessuno dei due, ma non possono avvenire entrambi), la probabilità che almeno uno dei due eventi si verifichi è la somma delle probabilità dei singoli eventi.
Nel nostro esempio la probabilità che un tiro dia come risultato 3 è di 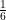
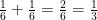
Nel caso di due eventi non mutuamente esclusivi, cioè eventi che possono avvenire contemporaneamente (ad esempio, che un tiro di dado dia come risultato un numero dispari oppure un numero maggiore di tre), la probabilità che almeno uno dei due eventi si verifichi è la somma delle probabilità dei singoli eventi meno la probabilità del fatto che si verifichino entrambi.
Nell’esempio, la probabilità che un tiro di dado dia come risultato un numero dispari è 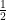

Ma, sento già arrivare l’obiezione, chi mi autorizza nei due esempi precedenti a ritenere che la probabilità giusta per l’evento “tirando un dado esce 5” sia proprio 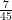

Mi autorizza il fatto che io guardo il dado, vedo che ha tutte le facce uguali, che non sembra che pesi più da una parte che dall’altra. Magari faccio un po’ di misure con una bilancia di precisione e verifico che il suo baricentro corrisponde al centro geometrico e non ha caratteristiche magnetiche asimmetriche. In altre parole, lo studio del dado non mi porta ad aspettarmi che una faccia sia favorita o sfavorita rispetto alle altre. Di conseguenza, la mia aspettativa rispetto al fatto che esca 1 è uguale all’aspettativa che esca 2, 3 e così via fino a 6.
Ma se le aspettative per i sei esiti possibili sono uguali, allora dovranno essere uguali anche le probabilità assegnate a quegli esiti. Quindi ho sei esiti possibili, mutuamente esclusivi, tutti con la stessa probabilità, e con il vincolo che si deve verificare con assoluta certezza almeno uno di quegli esiti.
La probabilità che si verifichi almeno uno di sei eventi equiprobabili mutuamente esclusivi è sei volte la probabilità di ciascuno di essi.
La probabilità di un evento certo (che tirando il dado esca almeno uno dei numero da 1 a 6) è 1, per definizione.
Quindi la probabilità che esca ciascuno dei sei esiti possibili, moltiplicata per 6 deve dare 1, quindi la probabilità di ciascuno degli esiti è
La probabilità bayesiana non soffre della limitazione della definizione frequentista, di non essere rigorosamente applicabile a eventi unici; possiamo anche utilizzarla in casi ancora più estremi, nei quali non è possibile costruire una serie frequentista neanche ricorrendo a casi simili – qual è la probabilità che il Sole diventi troppo caldo per permettere la vita sulla Terra nel corso del prossimo miliardo di anni?
L’altra grave obiezione possibile è che con questa definizione abbiamo reso la probabilità un concetto soggettivo! E la risposta corretta è: “Sì, e allora?”
Un autentico bayesiano non dovrebbe essere minimamente preoccupato da questa obiezione, perché lui sa che la probabilità non è un attributo del fatto osservato, ma quantifica le informazioni in possesso dell’osservatore – La probabilità è nella mappa, non nel territorio. Prendiamo un altro esempio: qual è la probabilità che ci sia vita su Titano, il satellite di Saturno?
Da un punto di vista puramente frequentista la domanda precedente non ha nessun senso: qui non è neanche questione di provare molte volte e contare i risultati; il fatto V che su Titano ci sia vita è o vero o falso. È già vero o già falso, quindi da un punto di vista oggettivo la sua probabilità può essere 0 o essere 1, non 0,173.
È solo da un punto di vista bayesiano che la domanda ha un senso: se tu potessi andare a vedere, ora, se c’è vita su Titano, cosa ti aspetteresti di trovare? Quantifica la tua aspettativa di trovarla o non trovarla.
Naturalmente anche questa definizione ha degli svantaggi importanti, e nascono proprio dalla sua natura di stima soggettiva: la probabilità di un evento può avere per me e per un’altra persona valori diversi: dipende dalle conoscenze di cui disponiamo (in gergo bayesiano queste informazioni sul territorio si chiamano priori). E non si può risolvere il problema dicendo che le nostre sono solo stime personali di una probabilità oggettiva, perché abbiamo reso la probabilità soggettiva per definizione e quindi, dal punto di vista bayesiano, non esiste una probabilità oggettiva.
Nell’uso pratico, quello che si fa veramente è usare entrambe le definizioni – frequentista e bayesiana – a seconda delle occasioni. L’importante è non dimenticare che sono due definizioni distinte, che rappresentano cose distinte, e che è solo il nostro cervello e la nostra cultura che cerca di convincerci che siano la stessa cosa.
Così ad esempio posso stimare la probabilità che domani piova facendo un’analisi frequentista su una serie storica, basata su un campione scelto sulla base di una ipotesi bayesiana sulla sua omogeneità. Oppure, e lo vedremo nell’articolo di Eliezer sul Teorema di Bayes, posso fare analisi bayesiane partendo da stime iniziali basate sui risultati di un’analisi frequentista.
L’importante, come dicevo, è di non dimenticare mai che si tratta di due cose diverse, anche se apparentemente sono la stessa cosa.
Un’ultima nota riguardo alla notazione numerica delle probabilità, siano esse frequentiste o bayesiane. Dal punto di vista matematico una probabilità è sempre un numero compreso tra 0 e 1; 0 è la probabilità di un evento che non si può verificare mai, 1 è la probabilità associata a un evento assolutamente certo. Probabilità con valori minori di 0 o maggiori di 1 non hanno matematicamente nessun senso.
Nell’uso comune siamo abituati a parlare di probabilità in termini di percentuali: se lancio una moneta, la probabilità che esca testa è P=50%; in base alle definizioni che abbiamo dato sopra la probabilità dell’evento “testa” è invece P=0,5. Come si spiega?
Semplicemente con il fatto che “percento” è un fattore di scala. Se sostituiamo il simbolo “%” con “diviso 100” vediamo che le due quantità sono in realtà uguali: 50% = 50/100 = 0,5.
L’uso della notazione percentuale deriva dalla definizione frequentista di probabilità: se lancio una moneta mi posso aspettare testa 50 volte su 100, o 50 volte per 100 che si contrae in 50 per 100 o 50%.
È solo una questione di notazione: non c’è nessuna differenza a dire che la probabilità è 0,5 o dire che è 50%. La prima notazione è più comoda per fare i calcoli, mentre la seconda è più pratica nell’uso corrente perché, in genere, permette di fare a meno della virgola decimale – nella maggior parte dei casi reali, approssimare una probabilità alla seconda cifra è più che sufficiente.
E adesso vi lascio alla prima parte dell’articolo di Eliezer Yudkowsky di introduzione al Teorema di Bayes.